Recently I’ve been considering making Java bindings to an open-source C library.
It’s such a pain though.
Update: On 2024-08-23, I wrote another post about this topic.
Native binding to C library
Traditionally you’d do this with JNI:
- Compile the C library,
- Write some JNI glue in C and Java,
- Package it all up into a JAR
Writing JNI isn’t trivial. I experimented with it and there are a lot of gotchas around memory management and string handling. I’m confident I could manage it but it’s a lot of work even to just move a UTF-8 string from C into Java without leaking memory or mis-handling exceptions.
Java 22 reached General Availability recently (March 2024) and it includes the first non-preview release of the Java Foreign Function and Memory (FFM) API, which is like a libffi or Python ctypes mechanism for Java - which Java Native Access (JNA) also already provided.
With that approach, you don’t write any glue code in C: Instead, you describe the C library’s exports in Java and use FFM/JNA to access them.
So then, your process looks like:
- Compile the C library,
- Write FFM/JNA glue in Java,
- Package it all up into a JAR
It’s still not perfect, though. In C, you can have platform- and implementation-dependent definitions of primitive types, standard library types and typedefs, etc. In C, these are resolved at compile time, so JNI gives you the opportunity to adapt to the platform’s specifications in a general way.
I wrote about this problem before: Using setjmp/longjmp from Java.
setjmp is a pretty obscure example, though. Here’s an easier example: long int is 64 bits on Linux x86_64, but 32 bits on Windows x86_64, and also on both Linux & Windows x86_32. So if you want to call unsigned long strtoul(...), you need to know how big unsigned long is at runtime when you’re describing strtoul to FFM/JNA.
In theory, types and sizes will vary depending on:
- Operating system (Linux, Windows, macOS, …)
- C library (glibc, musl, MSVC, …)
- Compiler (gcc, clang, Visual C++, …)
The above typically choose different behaviour depending on CPU architecture (x86_32, x86_64, 64-bit ARM, …)
Compile the C library
The C library you’re wrapping also needs to be compiled to match all of the above too.
Most Linux distributions standardize on glibc, but musl is also common (like on Alpine Linux, which is extremely common in Docker images).
Practically speaking, you’ll need to link dynamically against the same C library that’s being used on the system. If you bring another C library in (like through static linking, or including it as a pre-packaged dynamic library), you’re likely to encounter conflicts with the system-installed library.
You can avoid that problem with statically-linked executables, but libraries are not executables, so they have less control over their immediate execution environment. That is, they need to stay compatible with other libraries that are also linked into the same project, which are certainly using the system C library.
More precisely, you need to link against a version of the C library that is ABI-compatible with the one that’s present at runtime: If I compile my library against glibc 2.13 x86_64 Linux, I can be pretty confident it’ll run on glibc 2.15 x86_64 Linux, because glibc is backward-compatible. However, glibc is not forward-compatible, so it won’t run on glibc 2.10 x86_64 Linux. And of course, it won’t work on x86_32, musl, etc.
This doesn’t apply to JUST the C library, but any dependency you need to link against. That could include a C++ standard library or other more exotic dependencies, depending on the library you’re trying to wrap.
And since Java is used on so many different platforms…
… you end up having to compile your library for every possible combination you’re willing to support.
Look at the matrix of SQLite-JDBC supported operating systems:
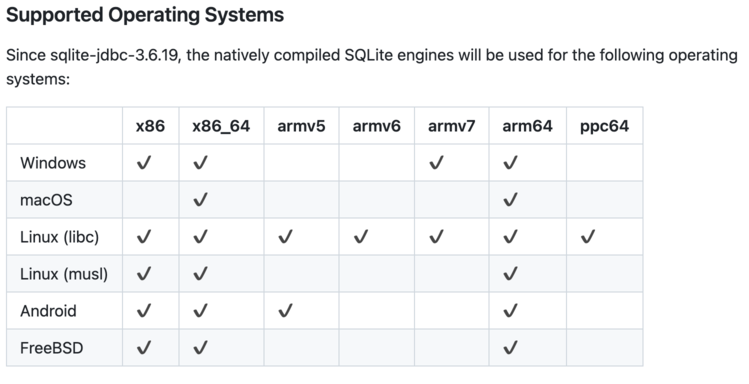
They compile the SQLite C library separately for each of those targets! You can peek at the platform targets in the Makefile for a hint on how they’re cross-compiling. I find their approach very impressive, but it sure seems like a lot of work to maintain!
Translate to JVM
Emscripten compiles C code and libraries to Javascript. At a very high level, it does this by providing C standard library functionality (primarily, the functionality provided by the OS kernel), and using JS/WASM as the compilation target.
In JS, you basically have no choice: You can’t run native code in the Javascript sandbox, so you have to provide everything as JS code.
You’d expect a performance hit for this, but that’s OK for a lot of libraries. This is true for me, too: The library I want to provide in Java provides unique functionality, and doesn’t necessarily need to run fast.
So I’d like to use a similar approach in Java:
- Compile a C library to JVM bytecode (or even plain Java code),
- Write glue to provide a better Java-style interface,
- Package it all up as a JAR
This is totally feasible. I’ve found two projects that use translation to achieve this:
- LLJVM translates LLVM IR (bitcode) to Java bytecode and provides C library via newlib & custom Java. Inactive since ~2010.
- NestedVM translates MIPS binaries to Java bytecode. GCC can create MIPS binaries. Inactive since ~2009 with some more recent updates available on a fork.
A lot of the discourse I’ve read focuses on how people want to call native C libraries from Java because the native code is expected to perform better, so this kind of “translation” approach typically gets dismissed: Why write your high-performance code in C in the first place if you’re going to run it in the JVM?
The library I want to wrap:
- Doesn’t require high performance
- Wasn’t written by me, so I didn’t have the choice to write it in Java vs. C
- Has unique and specialized functionality that’s hard to replicate
- Already works in Emscripten
So I’d love to try a translation approach and see how it works. It has some pretty significant advantages over using a native library:
- No difficulty compiling for all platform, OS, CPU architecture, compiler, and standard library configurations
- No difficulty porting, running, and testing on obscure platforms/configurations
- Low maintenance: Java code, even compiled, typically ages well and works unmodified for years/decades
It sounds absolutely delightful!